

What are Convolutional Neural Networks (CNN)? The Art of Computer Vision For Beginners
Suggested Blogs

Fascinated by the idea of computers understanding images and patterns? Convolutional Neural Networks are one of the most popular neural networks which handle analysis of visual imagery.
In this guide you’ll learn:
- What are Convolutional Neural Networks
- Convolutional Neural Network’s Architecture
- Convolutional Neural Network Layers
- Convolutional Layer
- Pooling Layer
- Fully-Connected Layer
What are Convolutional Neural Networks
Convolutional Neural Network or CNN, is a type of neural networks mainly used for computer vision tasks. Thanks to its architecture, CNN is able to pick out and detect patterns and understand images by looking at one patch of an image at a time by using multiple layers of filters and matrix dot operations which we will cover in-depth later in the article.
Convolutional Neural Network’s Architecture
Unlike regular neural networks, CNNs have unique architectures where the pixels of images given become the neurons and use special type of layers to process images and achieve desired results. That comes from the fact that processing images in NNs is possible but it would lead to very heavy computation for worse results.
Imagine you have an image of a cat with dimensions of 6*6*3 (6 wide, 6 high, 3 RGB color channels), to process the image in a regular neural network we would have to flatten the image so every pixel would be in one long 1D matrix and that becomes the input layer. However if we take as example 100 nodes in first hidden layer that would add up to 108 input nodes and 10800 weights connecting to first layer alone, now imagine if we took a real world sized image of at least 200*200*3 , that would lead to very heavy computation for only first layer without taking in consideration the rest of the hidden layers.
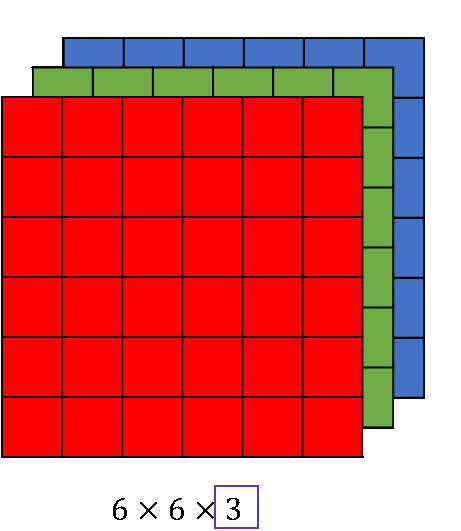
Example of an image with 6*6*3 dimensions
Convolutional Neural Network Layers
Diving deeper into CNNs architecture we would come across its main building blocks. Three special layers designed to handle processing images:
Convolutional Layer
Holds most of the computational heavy lifting, the convolutional layer’s task is the learning and detection of features from a given image using learnable filters.
Filters are dimensionally small matrixes that slide over input image pixels performing matrix dot product operations on their way to transform the pixels to highlight certain features producing convolved features that get aggregated to feature maps.
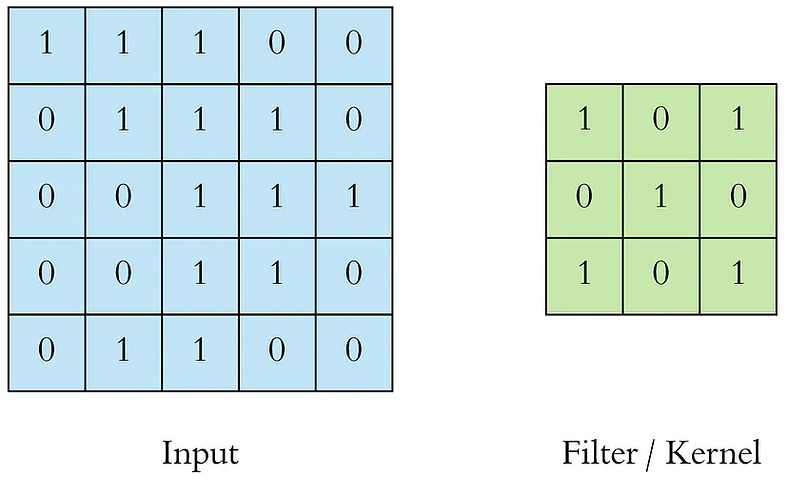
Left: example of input pixels of an image
Right: 3*3 dimension filter
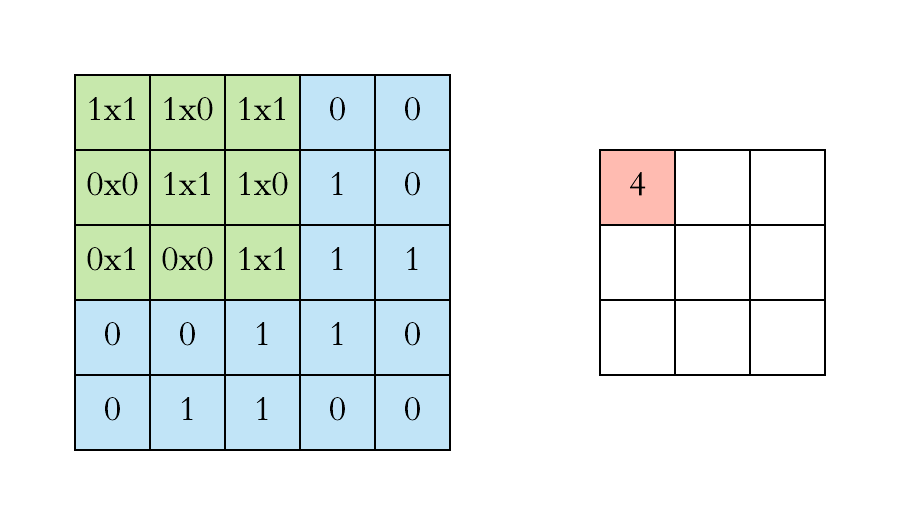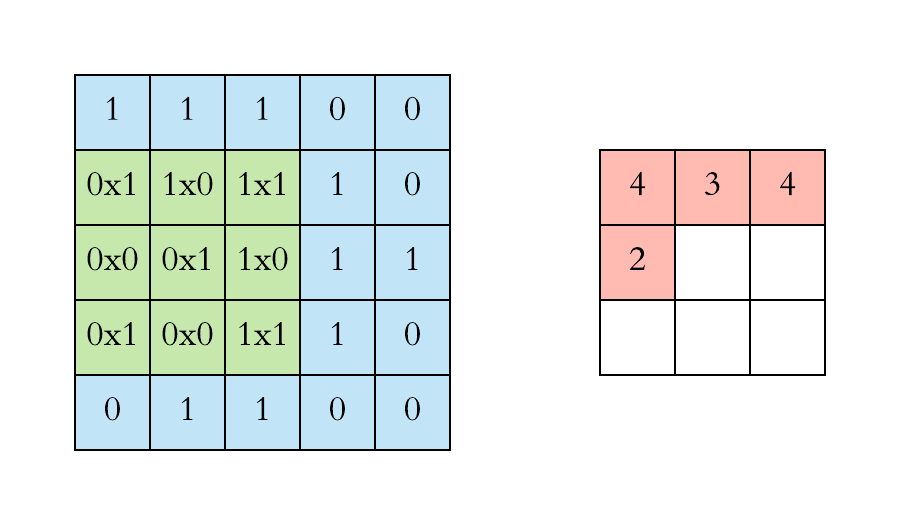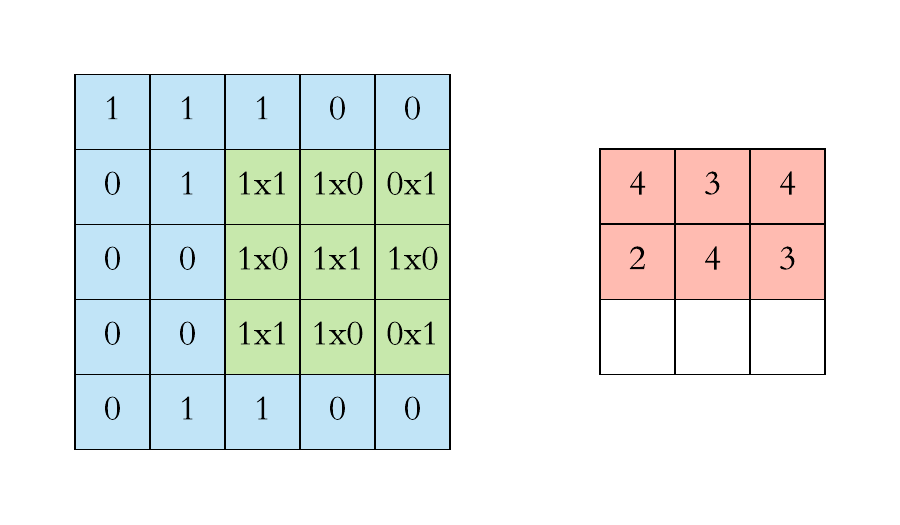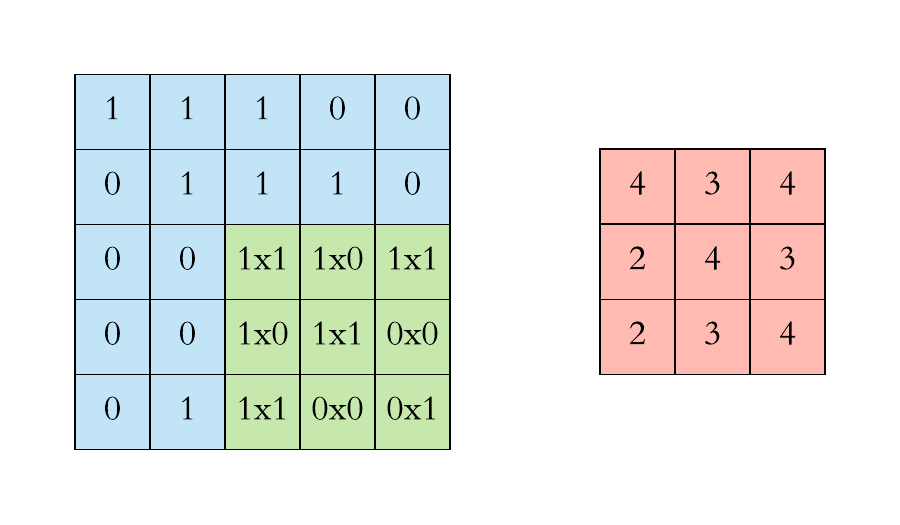
Example of how the filter slides across the image and calculates the feature maps
However a single convolutional layer won’t be enough to recognize objects or complex features because that is produced by multiple convolutional layers each using the last layer’s output as its input also know as feature hierarchy, where the first input layers start recognizing edges (horizontal/vertical lines), gradients and as you go deeper into more convolutional layers, it starts detecting outlines of objects until it becomes able to detect the complex feature or object.

Here (a) are the input images of moths and (b,c,d,e,f) are feature maps or results after going each through a convolutional layer, we can see that it starts detecting lines and outlines then as it progress through the layers it starts detecting the full moth in the image.
Note the at the values called weights inside the filter matrix stay the same as it slides across the image that is because the filter is being used to find a certain feature like vertical lines it would be reasonable to keep that filter the same throughout the whole image so it detects the vertical lines in every part of the image, that is called parameter sharing. However it would be beneficial to not use it in some cases, for instance detecting human faces in certain places it is better to use filters optimized for eye regions to detect eyes and use different valued filters optimized for mouth regions to detect mouths.
There are more parameters that can be tuned in convolutional layers like:
- Number of filters: The number of filters applied on each part of the image, this enables the layer to find and learn a diverse set of features from multiple filters. However using more filters comes with more computational cost.
- Stride: The distance that the filter matrix moves across the image each time, the majority of stride values don’t exceed 2 because it can cause information loss.
- Zero-Padding: Pads the input image by adding zeros to the edges when the filters don’t fit in the size of the input image.
Pooling Layer
Also known as downsampling, it performs dimensionality reduction to remove unwanted noise and features in the feature maps as well as reduce computational power. Mostly used after every convolutional layer.
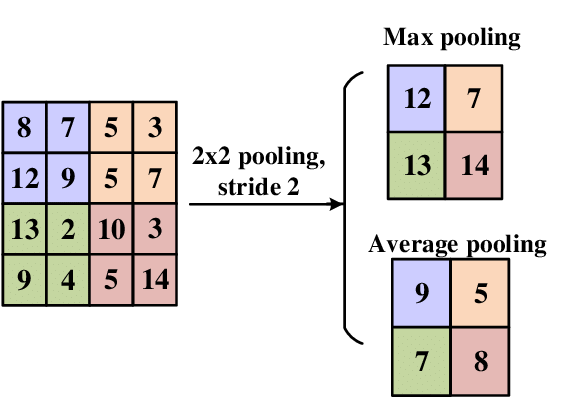
Max pooling: moves through the image and takes the maximum pixel value of every size defined region.
Average pooling: moves through the image and calculates the average of the pixel values in every size defined region.
Note: Max pooling performs better than average pooling.
Fully-Connected Layer
Flattens the resulted feature maps from 3D matrixes to 1D vector and uses every pixel as a neuron to pass to a classification neural network and re-intrdouces the concept of weights to perform the task of classification the features extracted.
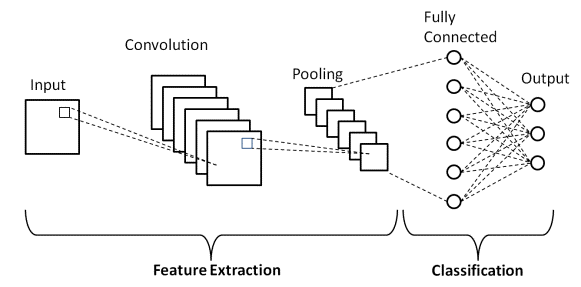
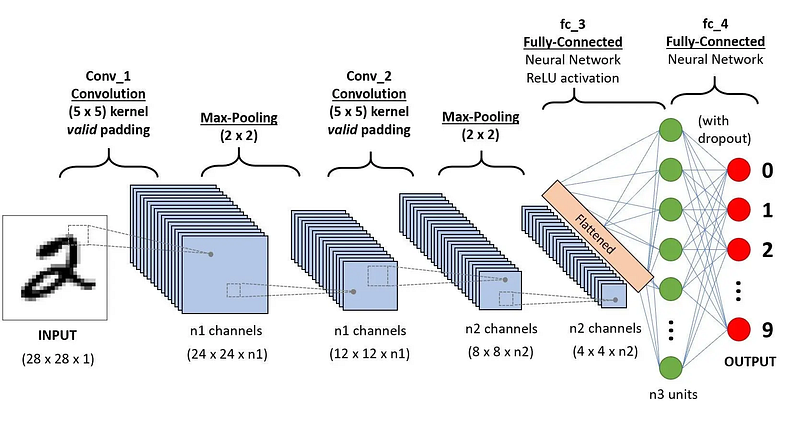
Example of a full CNN architecture
Final Thoughts
In this article, we’ve explored Convolutional Neural Networks (CNNS) and understood the architecture of CNNs, i avoided speaking about the limitations, activations functions and Regularization techniques as this article is aimed towards beginners. I covered these subjects in other articles, check References.
References:
What are Neural Networks? Deep Learning Explained for Beginners
Thank you for reading
Please feel free to share your thoughts, any errors will be corrected in the blog.