

What are Recurrent Neural Networks (CNN)? Unlocking Sequences
Suggested Blogs

Ever wondered how Chat-GPT or Siri are capable of understanding and responding to human language? Recurrent neural networks enables machines to grasp context.
In this guide, you’ll learn:
- What are Recurrent Neural Networks
- Recurrent Neural Network’s Architecture
- Types of recurrent neural networks
- Variants of Recurrent Neural Networks
What are Recurrent Neural Networks
Recurrent Neural Networks (RNNs), are a type of neural networks that handle sequential data or time series data, It is used for tasks that require the computer to have context or keep a bit of memory such as speech recognition, language translation, image captioning. Take for example speech recognition, The meaning of individual words often depends on the words that came before them. For instance, “The cat sat on the mat”, Understand the phrase “sat on the mat” requires knowledge of the preceding words “The cat” to know the subject that performed the action.
Recurrent Neural Network’s Architecture
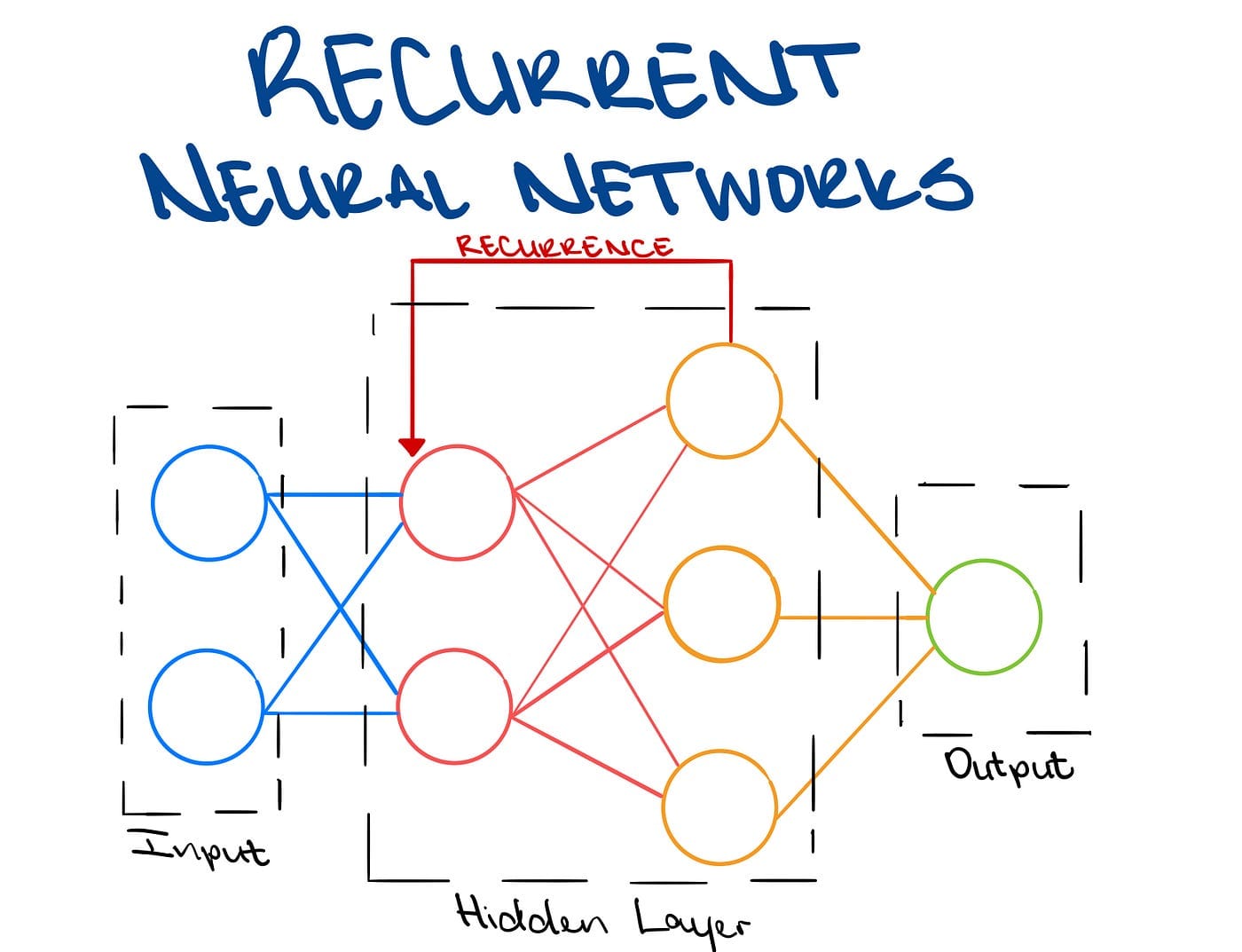
Since RNNs need the ability to remember previous input data, The architecture is quite difference from a feed forward neural network where input data goes straight through layers to the output layer. The main change is the Hidden State which remembers some information from the sequence given.
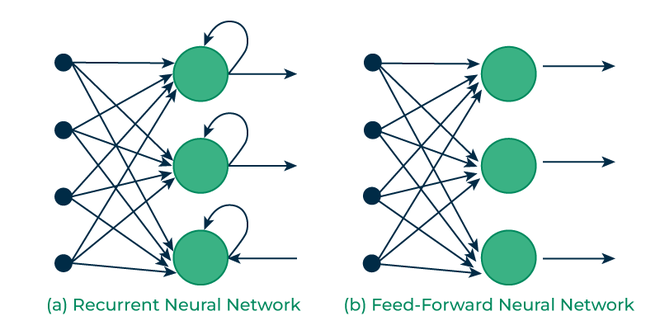
Difference between RNNs and Feed-Forward Neural Networks
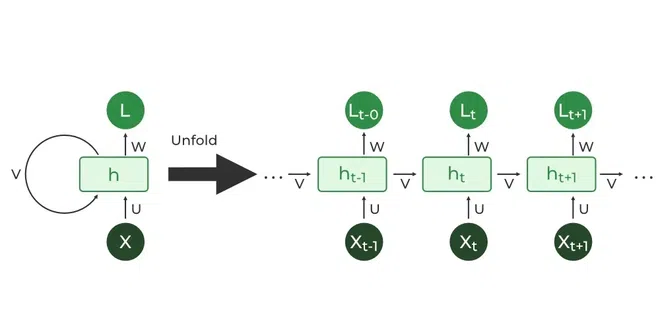
The RNNs architecture has looping nodes that allow the outputs to be used as inputs which enables the network to maintain an internal memory of past inputs. To further conceptualize the idea of looping nodes we can unroll the neural network.
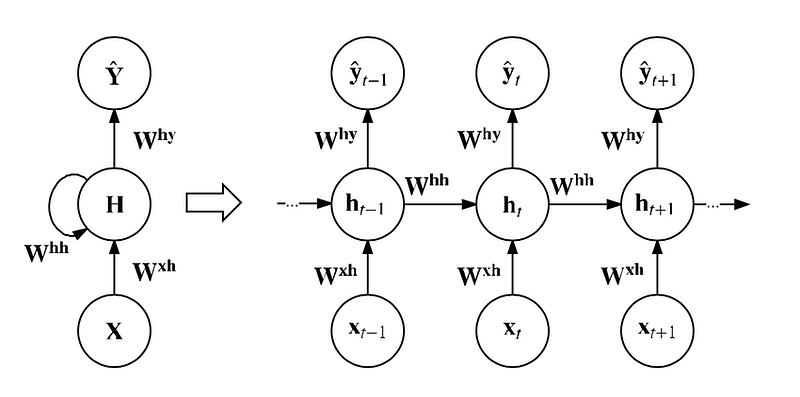
Example of how the loop is unrolled
Y: The output of each node which is used as input for next node with the new input data
H: Hidden State
X: The input
Another interesting characteristic of RNNs is that they share parameters, unlike feedforward networks recurrent neural networks share the same weight parameter within each layer of the network. Which as a result reduces model complexity, computational complexity and lowers the chance of overfitting.
Overfitting: When a model performs incredibly well on training data and poorly on unseen data.
However parameter sharing introduces two new problems knows as Exploding Gradients and Vanishing Gradients.
Exploding Gradients
Without going into a lot of maths as this is for a beginner, when neural networks calculate outputs for each node the main equation that happens under the hood is:
node_output = xW + b
Where x, W and b are the input from a node , weight that connects the input node to the next node in the next layer and the bias respectively. But to learn the neural network has to perform Back Propagation, Broadly it calculates the difference between the real output and the predicted output and uses that to change the weights to perform better in the next pass. Now when we set the shared weights to a value greater than 1, with all the calculations thats happening and repeating because of the loop the weight values will grow exponentially which will cause large changes in the outputs even when the input change is small and it will make the outputs inaccurate.
Vanishing Gradients
Vanishing Gradients is the opposite of Exploding Gradients, it occurs when we set the weights very close to zero. Resulting in the weights becoming very small through iterations making learning very hard for the neural networks.
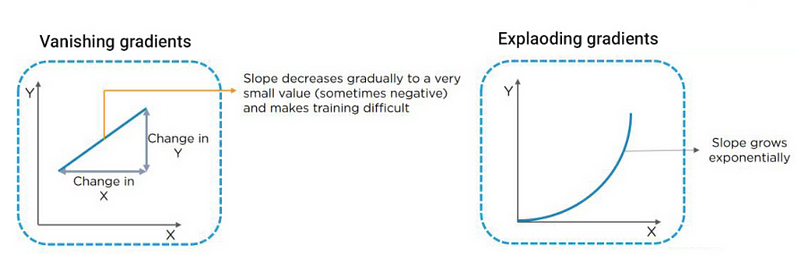
Graphical explanation of Vanishing Gradients and Exploading Gradients
Types of recurrent neural network
RNNs can be categorized based on the relationship between their input and output sequences. Here are some common types:
- One-to-One (Vanilla) RNN:
- Simples form of an RNN, where there is a one-to-one mapping between input and output.
- Example: Classifying an image (input) into categories (output) using an RNN.
2. One-to-Many RNN:
- In this type, a single input is used to generate a sequence of outputs.
- Example: Generating captions for an image. The input is the image, and the output is a sequence of words describing the image.
3. Many-to-One RNN:
- Here, a sequence of inputs is used to generate a single output.
- Example: Sentiment analysis of a movie review. The input is a sequence of words (review), and the output is the sentiment (positive or negative).
4. Many-to-Many (Same Length) RNN:
- Both the input and output sequences have the same length.
- Example: Named Entity Recognition (NER). The input is a sequence of words, and the output is a sequence of labels indicating named entities (e.g., person, organization).
5. Many-to-Many (Different Length) RNN:
- Input and output sequences have different lengths.
- Example: Machine translation. The input is a sequence of words in one language, and the output is a sequence of words in another language, which may have different lengths.
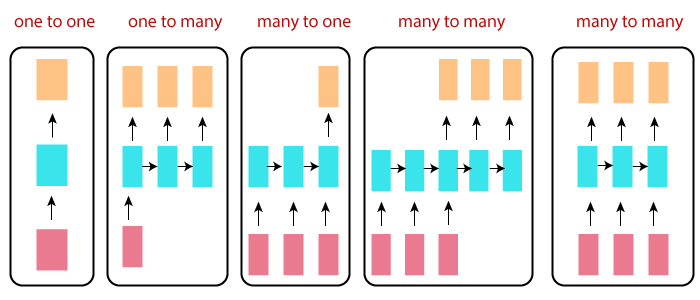
Variants of Recurrent Neural Networks
Bidirectional recurrent neural networks (BRNN): These are a variant network architecture of RNNs. While unidirectional RNNs can only drawn from previous inputs to make predictions about the current state, bidirectional RNNs pull in future data to improve the accuracy of it. If we return to the example of “the cat sat on the mat”, the model can predict that the second word is “cat” if it knew the next word is “sat”.
Long short-term memory (LSTM): A popular RNN architecture, that solves the problems of the short term memory and vanishing gradients a regular RNN has. For instance when typing on smartphone keyboard, the keyboard suggests predicts your next word based on what you typed so far and the context of the sentence.
Gated recurrent units (GRUs): This RNN variant is similar the LSTMs as it also works to address the short-term memory problem of RNN models. Instead of using a “cell state” regulate information, it uses hidden states, and instead of three gates, it has two — a reset gate and an update gate. Similar to the gates within LSTMs, the reset and update gates control how much and which information to retain.
Final Thoughts
In this beginner-friendly guide, we covered recurrent neural networks from it’s architecture to the types of different RNNs. Although i had to use concepts like back propagation and some maths, this just covers broadly the training process and learning. In future articles, we’ll cover complex mathematical explanations of these concepts.
References:
What are Neural Networks? Deep Learning Explained for Beginners
What are Convolutional Neural Networks (CNN)? The Art of Computer Vision For Beginners
Thank you for reading
Please feel free to share your thoughts, any errors will be corrected in the blog.